Define crosswalks with actions & transform data¶
Definition
Crosswalks are mappings of the relationships between fields defined in different metadata schemas. Ideally, these are one-to-one, where a field in one has an exact match in the other. In practice, it's more complicated than that.
whyqd (/wɪkɪd/) reduces crosswalks to a series of action scripts, each defining an individual step which must be performed to restructure source- into a destination data.
All scripts are written as a text string conforming to a standardised template:
Script template
"ACTION > 'destination_field'::'destination_term' < 'source_term'::['source_field', 'source_field']"
Less formally: "Perform this action to create this destination field from these source fields."
Actions are a wrapper around the underlying Pandas API.
Example
"SEPARATE > ['new_1', 'new_2', 'new_3', 'new_4'] < ';;'::['separate_column']"
Will transform:
| ID | separate_column |
|---|---|
| 2 | Dogs;;Cats;;Fish |
| 3 | Cats;;Bats;;Hats;;Mats |
| 4 | Sharks;;Crabs |
Bitwise into each destination field.
| ID | separate_column | new_1 | new_2 | new_3 | new_4 |
|---|---|---|---|---|---|
| 2 | Dogs;;Cats;;Fish | Dogs | Cats | Fish | |
| 3 | Cats;;Bats;;Hats;;Mats | Cats | Bats | Hats | Mats |
| 4 | Sharks;;Crabs | Sharks | Crabs |
And that one-line script is a wrapper for:
separate_array = np.array([x.split(source_param) for x in df[source[0].name].array.ravel()], dtype=object)
num_columns = max(map(len, separate_array))
if num_columns == 1:
return df
if not isinstance(destination, list) or num_columns != len(destination):
raise ValueError(
f"SEPARATE action needs to split {num_columns} columns by received {len(destination)} for destination."
)
new_columns = [c.name for c in destination]
df[new_columns] = df[source[0].name].str.split(source_param, expand=True)
API
Review the class API definitions: CrosswalkDefinition, CRUDAction and
TransformDefinition.
Strategy & purpose for crosswalk transforms¶
Strategy
Crosswalks must be explicit rather than implicit.
Describe all transforms in scripts. Performing each action in sequence must transform your source data to your destination data with no other hidden assumptions or actions required.
whyqd will support you through consistency and predictability. It will always run scripts the same way each time.
Curation is about recognising contextual requirements. Looking at your source data as it is. Updating rows in a database is far easier than adding in new columns / fields. Yet people find it easier to "read" data like text (so in the direction of travel - right-to-left or left-to-right, depending on language).
When you look at source data, do so with an eye to structure and not analysis:
- Do you have merged headers spanning multiple columns and rows?
- Are categorical terms defined as sub-header data rows instead of as independent fields?
- Are values overloaded, containing both quantitative and qualitative data (such as a term and a date)?
- Has contextual information been included as redundant rows above or below your data?
- Are your data wide or long?
When data are particularly messy, don't try and go straight to your final schema. First transform your source into an interim form which supports its actual structure.
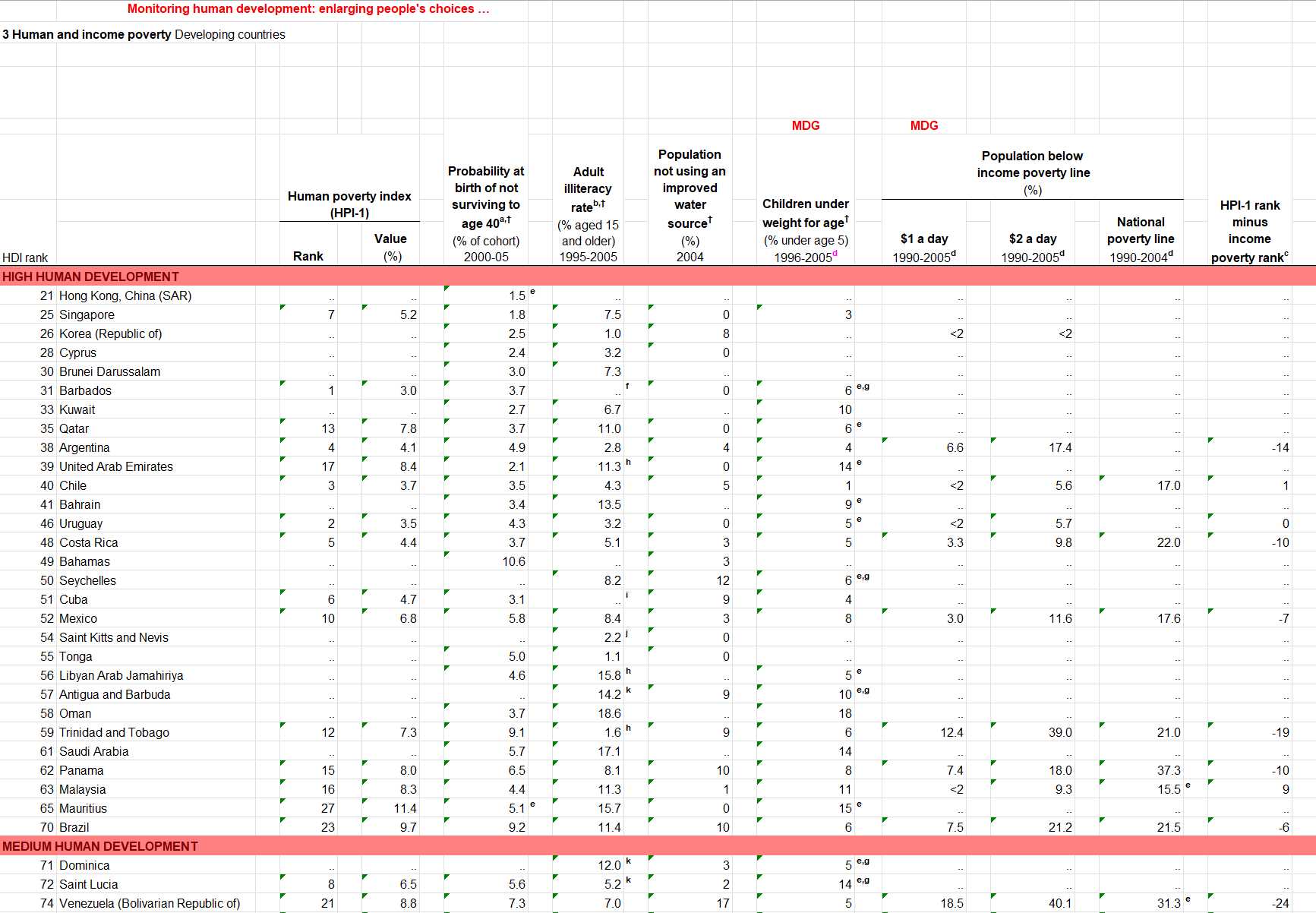
This spreadsheet is in wide format. Creating a crosswalk to get it into a well-behaved interim form will make pivoting into a long form much easier.
whyqd will be doing the repetitive work. Slow down and think it through.
Action scripting summary¶
Actions use similar naming conventions as for R's Tidyr and should be self-explanatory. Each has definitions and examples you can review:
| Action | > Field |
> Term |
< Term |
< Field |
< Rows |
|---|---|---|---|---|---|
| CALCULATE | X | [m X,] | |||
| CATEGORISE | X | X | [X,] | X | |
| COLLATE | X | [X, m,] | |||
| DEBLANK | |||||
| DEDUPE | |||||
| DELETE_ROWS | [X,] | ||||
| NEW | X | [X] | |||
| PIVOT_CATEGORIES | X | X | [X,] | ||
| PIVOT_LONGER | [X, X] | [X,] | |||
| RENAME | X | [X] | |||
| SELECT | X | [X,] | |||
| SELECT_NEWEST | X | [X m X,] | X | ||
| SELECT_OLDEST | X | [X m X,] | |||
| SEPARATE | [X,] | X | [X] | ||
| UNITE | X | X | [X,] |
Here:
Xrequires only a single term,[X]only a single term, but inside square brackets,[X, X]only two terms accepted,[X,]accepts any number of terms,[m X,]any number of terms, but each term requires a modifier,[X m X,]any number of terms, but indicates a relationship between two terms defined by a modifier,[X, m,]any number of terms or modifiers, in any combination.
Example
Modifiers should be self-explanatory, and this calculation script should be easy to read:
"CALCULATE > 'total' < [+ 'income', - 'expenses']"
A script field is always a term defined in the source- or destination schema. A script term is context-specific. It
could be used to indicate categories, or text for splitting. A script modifier is usually a + or - and is context-
specific.
row terms are indexed, meaning they must be in the source table or the script will fail.
Tutorials
It is assumed that you're not working 'blind', that you're actually looking at your data while assigning actions - especially row-level actions - otherwise you are going to get extremely erratic results. whyqd is built on Pandas and these examples lean heavily on that package.
There are three worked tutorials that guide you through three typical scenarios, and you may find them helpful:
Continuous Integration and automating crosswalks¶
Crosswalks are deliberately distinct from transforms.
A crosswalk contains only the definitions for a source- and destination schema, and the action scripts that define the relationship between them.
This makes it easy to use a .crosswalk definition as part of a continuous integration process, where data are harvested
automatically, assigned a crosswalk, and output data transforms imported into a database.
Performing transformations¶
Assume you have data that looks like this:
| Country Name | Country Code | Indicator Name | Indicator Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aruba | ABW | Urban population | SP.URB.TOTL | 27526 | 28141 | 28532 | 28761 | 28924 | 29082 | 29253 | 29416 | 29575 | 29738 | 29900 | 30082 | 30275 | 30470 | 30605 | 30661 | 30615 | 30495 | 30353 | 30282 | 30332 | 30560 | 30943 | 31365 | 31676 | 31762 | 31560 | 31142 | 30753 | 30720 | 31273 | 32507 | 34116 | 35953 | 37719 | 39172 | 40232 | 40970 | 41488 | 41945 | 42444 | 43048 | 43670 | 44246 | 44669 | 44889 | 44882 | 44686 | 44378 | 44053 | 43778 | 43819 | 44057 | 44348 | 44665 | 44979 | 45296 | 45616 | 45948 | nan |
| Afghanistan | AFG | Urban population | SP.URB.TOTL | 755836 | 796272 | 839385 | 885228 | 934135 | 986074 | 1.04119e+06 | 1.09927e+06 | 1.16136e+06 | 1.22827e+06 | 1.30095e+06 | 1.37946e+06 | 1.46329e+06 | 1.55104e+06 | 1.64087e+06 | 1.73093e+06 | 1.82161e+06 | 1.91208e+06 | 1.99758e+06 | 2.07094e+06 | 2.13637e+06 | 2.18149e+06 | 2.20897e+06 | 2.22507e+06 | 2.24132e+06 | 2.2679e+06 | 2.30581e+06 | 2.35734e+06 | 2.43955e+06 | 2.50291e+06 | 2.62855e+06 | 2.82817e+06 | 3.09339e+06 | 3.39171e+06 | 3.67709e+06 | 3.91625e+06 | 4.09384e+06 | 4.22082e+06 | 4.32158e+06 | 4.43476e+06 | 4.5878e+06 | 4.79005e+06 | 5.03116e+06 | 5.29338e+06 | 5.5635e+06 | 5.82429e+06 | 6.05502e+06 | 6.26375e+06 | 6.46484e+06 | 6.68073e+06 | 6.92776e+06 | 7.21252e+06 | 7.52859e+06 | 7.86507e+06 | 8.20488e+06 | 8.53561e+06 | 8.85286e+06 | 9.16484e+06 | 9.4771e+06 | nan |
| Angola | AGO | Urban population | SP.URB.TOTL | 569222 | 597288 | 628381 | 660180 | 691532 | 721552 | 749534 | 776116 | 804107 | 837758 | 881022 | 944294 | 1.0282e+06 | 1.12462e+06 | 1.23071e+06 | 1.34355e+06 | 1.4626e+06 | 1.58871e+06 | 1.72346e+06 | 1.86883e+06 | 2.02677e+06 | 2.19787e+06 | 2.38256e+06 | 2.58126e+06 | 2.79453e+06 | 3.02227e+06 | 3.26559e+06 | 3.5251e+06 | 3.8011e+06 | 4.09291e+06 | 4.40096e+06 | 4.72563e+06 | 5.06788e+06 | 5.42758e+06 | 5.80661e+06 | 6.15946e+06 | 6.53015e+06 | 6.919e+06 | 7.32807e+06 | 7.75842e+06 | 8.212e+06 | 8.68876e+06 | 9.19086e+06 | 9.72127e+06 | 1.02845e+07 | 1.08828e+07 | 1.14379e+07 | 1.20256e+07 | 1.26446e+07 | 1.32911e+07 | 1.39631e+07 | 1.46603e+07 | 1.53831e+07 | 1.61303e+07 | 1.69008e+07 | 1.76915e+07 | 1.85022e+07 | 1.93329e+07 | 2.01847e+07 | nan |
| Albania | ALB | Urban population | SP.URB.TOTL | 493982 | 513592 | 530766 | 547928 | 565248 | 582374 | 599300 | 616687 | 635924 | 656733 | 677801 | 698647 | 720649 | 742333 | 764166 | 786668 | 809052 | 832109 | 854618 | 876974 | 902120 | 927513 | 954645 | 982645 | 1.01124e+06 | 1.04013e+06 | 1.0685e+06 | 1.09835e+06 | 1.12772e+06 | 1.16716e+06 | 1.19722e+06 | 1.19891e+06 | 1.20949e+06 | 1.21988e+06 | 1.23022e+06 | 1.2404e+06 | 1.25052e+06 | 1.26041e+06 | 1.27021e+06 | 1.27985e+06 | 1.28939e+06 | 1.29858e+06 | 1.32722e+06 | 1.35485e+06 | 1.38183e+06 | 1.4073e+06 | 1.43089e+06 | 1.4524e+06 | 1.47339e+06 | 1.49526e+06 | 1.51952e+06 | 1.54693e+06 | 1.57579e+06 | 1.6035e+06 | 1.63012e+06 | 1.6545e+06 | 1.68025e+06 | 1.70634e+06 | 1.72897e+06 | nan |
You have other data, with other indicators and spanning different (but overlapping) years, and you want to merge all of them into a single analytical database.
Your workflow is:
- Define a single destination schema,
- Derive a source schema from each data source,
- Review the data structure and develop a crosswalk,
- Transform and validate your outputs.
There is a complete tutorial, and we'll focus only on the last two steps.
Assume the list of year headers is HEADER_YEARS. Your crosswalk scripts are:
SCRIPTS = [
"DEBLANK",
"DEDUPE",
"DELETE_ROWS < [0, 1, 2, 3]",
f"PIVOT_LONGER > ['year', 'values'] < {HEADER_YEARS}",
"RENAME > 'indicator_code' < ['Indicator Code']",
"RENAME > 'indicator_name' < ['Indicator Name']",
"RENAME > 'country_code' < ['Country Code']",
"RENAME > 'country_name' < ['Country Name']",
]
There are really only two complex actions here. This particular data source has a header row that is not zero-indexed, which is why we need to delete redundant rows. And then we pivot the year columns into year and value fields.
As code, assign this and perform your transformation as follows:
import whyqd as qd
# Crosswalk
crosswalk = qd.CrosswalkDefinition()
crosswalk.set(schema_source=schema_source, schema_destination=schema_destination)
crosswalk.actions.add_multi(terms=SCRIPTS)
crosswalk.save(directory=DIRECTORY)
# Transform
transform = qd.TransformDefinition(crosswalk=crosswalk, data_source=DATA_MODEL)
transform.process()
transform.save(directory=DIRECTORY)
Your output is a long form table:
| indicator_code | indicator_name | country_code | country_name | year | values |
|---|---|---|---|---|---|
| SP.URB.TOTL | Urban population | ABW | Aruba | 1960 | 27526 |
| SP.URB.TOTL | Urban population | AFG | Afghanistan | 1960 | 755836 |
| SP.URB.TOTL | Urban population | AGO | Angola | 1960 | 569222 |
| SP.URB.TOTL | Urban population | ALB | Albania | 1960 | 493982 |
Your saved output is:
- A
.transformdefinition file that contains your source and destination schemas, the crosswalk that links them, as well as definitions for your source and destination data models. There is also a citation and a version history. - A data file in
.parquetformat with columns conforming to your destination schema field types.
You can share both and know that you are providing everything anyone would need to review, audit and rerun your crosswalk.
Validating crosswalks¶
Researchers may disagree on conclusions derived from analytical results. What they should not have cause for disagreement on is the probity of the underlying data used to produce those analytical results.
By sharing your .transforms alongside your data, you allow this:
from pathlib import Path
import whyqd as qd
DESTINATION_DATA = DIRECTORY / "data.parquet"
DESTINATION_MIMETYPE = "parquet"
TRANSFORM = DIRECTORY / "reference.transform"
valiform = qd.TransformDefinition()
valiform.validate(
transform=TRANSFORM, data_destination=DESTINATION_DATA, mimetype_destination=DESTINATION_MIMETYPE
)
True
Assuming the reference source data are available online (and referenced in the TRANSFORM model), then this will perform
the crosswalk from source, derive the destination data, and compare the checksums of the data your provided with what it
should have been. If everything matches, you know that the source data does produce the destination data.
If the source data are offline (or unreachable), simply provide it. Validation also checks that the source matches what it should have been originally.
import whyqd as qd
valiform = qd.TransformDefinition()
valiform.validate(
transform=TRANSFORM, data_destination=DESTINATION_DATA, mimetype_destination=DESTINATION_MIMETYPE,
data_source=SOURCE_DATA, mimetype_source=SOURCE_MIMETYPE
)
True
Validation errors are reported and try to indicate the reasons for failure.