Quick start¶
whyqd (/wɪkɪd/) reduces crosswalks to a series of action scripts, each defining an individual step which must be performed to restructure source- into a destination data.
Your workflow is:
- Define a single destination schema,
- Derive a source schema from a data source,
- Review your source data structure,
- Develop a crosswalk to define the relationship between source and destination,
- Transform and validate your outputs,
- Share your output data, transform definitions, and a citation.
Quick links
Define a schema model¶
Assume you want you destination schema to conform to this table structure:
| la_code | ba_ref | occupant_name | postcode | occupation_state | occupation_state_date | prop_ba_rates | occupation_state_reliefs |
|---|---|---|---|---|---|---|---|
| E06000044 | 177500080710 | A company | PO5 2SE | True | 2019-04-01 | 98530 | [small_business, retail] |
Define your model as follows:
import whyqd as qd
schema: qd.models.SchemaModel = {
"name": "rates_data",
"title": "Commercial rates data",
"description": "Standardised schema for archival and analysis of commercial / non-domestic rates data.",
}
fields: list[qd.models.FieldModel] = [
{
"name": "la_code",
"title": "Local authority code",
"type": "string",
"description": "Standard code for local authority."
},
{
"name": "ba_ref",
"title": "Billing reference",
"type": "string",
"description": "Unique code for a specific hereditament. May be multiple rows for history."
},
{
"name": "prop_ba_rates",
"title": "Property billing rates",
"type": "number",
"description": "Actual rates paid by a specific ratepayer."
},
{
"name": "occupant_name",
"title": "Occupier name",
"type": "string",
"description": "Name of the ratepayer."
},
{
"name": "postcode",
"title": "Postcode",
"type": "string",
"description": "Full address or postcode of ratepayer."
},
{
"name": "occupation_state",
"title": "Occupation state",
"type": "boolean",
"description": "Occupation status, void or occupied."
},
{
"name": "occupation_state_date",
"title": "Date of occupation state",
"type": "date",
"description": "Date of the start of status in occupation_state."
},
{
"name": "occupation_state_reliefs",
"title": "Occupation state reliefs",
"type": "array",
"description": "Array of the categories of reliefs / exemptions applied."
}
]
schema_destination = qd.SchemaDefinition()
schema_destination.set(schema=schema)
schema_destination.fields.add_multi(terms=fields)
schema_destination.save()
Derive a source schema from data¶
Assume we have multiple data sources with a variety of formats. One could be this:
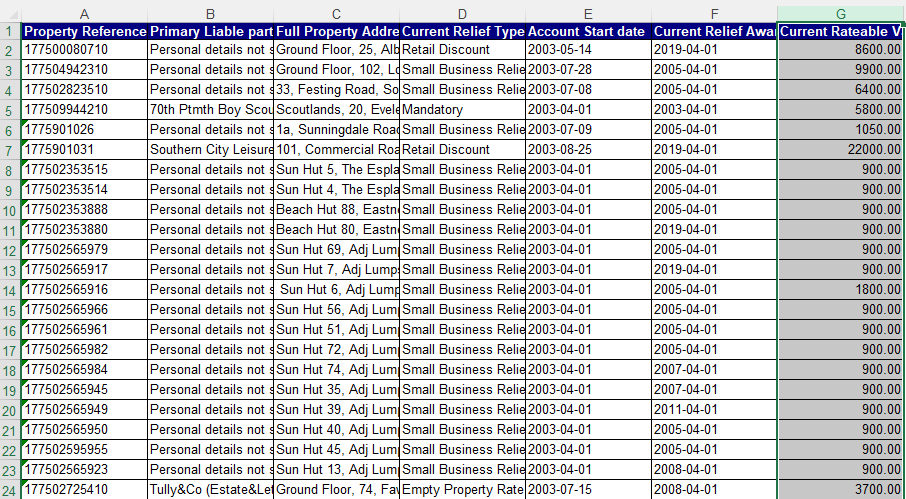
We import it from DATASOURCE_PATH, define its MIMETYPE, and derive a schema:
import whyqd as qd
datasource = qd.DataSourceDefinition()
datasource.derive_model(source=DATASOURCE_PATH, mimetype=MIMETYPE)
schema_source = qd.SchemaDefinition()
schema_source.derive_model(data=datasource.get)
schema_source.fields.set_categories(name=CATEGORY_FIELD,
terms=datasource.get_data())
schema_source.save()
Where the CATEGORY_FIELD is a string which identifies which data model column you want to get categorical terms from.
This will identify all the unique terms in that table column and assign them as categorical terms to the field.
Info
whyqd supports any of the following file mime types:
CSV: "text/csv"XLS: "application/vnd.ms-excel"XLSX: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"PARQUET(orPRQ): "application/vnd.apache.parquet"FEATHER(orFTR): "application/vnd.apache.feather"
Declare it like so:
MIMETYPE = "xlsx" # upper- or lower-case is fine
Specify the mime type as a text string, uppper- or lower-case. Neither of Parquet or Feather yet have official mimetypes, so this is what we're using for now.
Strategy quick links
Crosswalk scripting language¶
Your source- and destination schemas allow you to work rapidly, without reference to the underlying data.
All scripts are written as a text string conforming to a standardised template:
Script template
"ACTION > 'destination_field'::'destination_term' < 'source_term'::['source_field', 'source_field']"
Less formally: "Perform this action to create this destination field from these source fields."
Actions use similar naming conventions as for R's Tidyr. Each has definitions and examples you can review:
| Action | > Field |
> Term |
< Term |
< Field |
< Rows |
|---|---|---|---|---|---|
| CALCULATE | X | [m X,] | |||
| CATEGORISE | X | X | [X,] | X | |
| COLLATE | X | [X, m,] | |||
| DEBLANK | |||||
| DEDUPE | |||||
| DELETE_ROWS | [X,] | ||||
| NEW | X | [X] | |||
| PIVOT_CATEGORIES | X | X | [X,] | ||
| PIVOT_LONGER | [X, X] | [X,] | |||
| RENAME | X | [X] | |||
| SELECT | X | [X,] | |||
| SELECT_NEWEST | X | [X m X,] | X | ||
| SELECT_OLDEST | X | [X m X,] | |||
| SEPARATE | [X,] | X | [X] | ||
| UNITE | X | X | [X,] |
Here:
Xrequires only a single term,[X]only a single term, but inside square brackets,[X, X]only two terms accepted,[X,]accepts any number of terms,[m X,]any number of terms, but each term requires a modifier,[X m X,]any number of terms, but indicates a relationship between two terms defined by a modifier,[X, m,]any number of terms or modifiers, in any combination.
For your example, we define the crosswalk as:
SCRIPTS = [
"NEW > 'la_code' < ['E06000044']",
"RENAME > 'ba_ref' < ['Property Reference Number']",
"RENAME > 'prop_ba_rates' < ['Current Rateable Value']",
"RENAME > 'occupant_name' < ['Primary Liable party name']",
"RENAME > 'postcode' < ['Full Property Address']",
"CATEGORISE > 'occupation_state'::False < 'Current Relief Type'::['Empty Property Rate Non-Industrial', 'Empty Property Rate Industrial', 'Empty Property Rate Charitable']",
"CATEGORISE > 'occupation_state_reliefs'::'small_business' < 'Current Relief Type'::['Small Business Relief England', 'Sbre Extension For 12 Months', 'Supporting Small Business Relief']",
"CATEGORISE > 'occupation_state_reliefs'::'vacancy' < 'Current Relief Type'::['Empty Property Rate Non-Industrial', 'Empty Property Rate Industrial', 'Empty Property Rate Charitable']",
"CATEGORISE > 'occupation_state_reliefs'::'retail' < 'Current Relief Type'::['Retail Discount']",
"CATEGORISE > 'occupation_state_reliefs'::'other' < 'Current Relief Type'::['Sports Club (Registered CASC)', 'Mandatory']",
"SELECT_NEWEST > 'occupation_state_date' < ['Current Relief Award Start Date' + 'Current Relief Award Start Date', 'Account Start date' + 'Account Start date']",
]
We define the crosswalk as:
import whyqd as qd
crosswalk = qd.CrosswalkDefinition()
crosswalk.set(schema_source=SCHEMA_SOURCE, schema_destination=SCHEMA_DESTINATION)
crosswalk.actions.add_multi(terms=SCRIPTS)
crosswalk.save()
Strategy quick links
Transforms and validations¶
Performing the work to produce validated output data is only a few lines of code:
import whyqd as qd
# Transform a data source
transform = qd.TransformDefinition(crosswalk=crosswalk, data_source=DATA_SOURCE)
transform.process()
transform.save(directory=DIRECTORY)
# Validate a data source
valiform = qd.TransformDefinition()
valiform.validate(
transform=TRANSFORM, data_destination=DESTINATION_DATA, mimetype_destination=DESTINATION_MIMETYPE
)
Next steps¶
The code itself is relatively trivial. Where you need to spend time is in internalising the techniques you need to write concise crosswalk scripts.
You can continue from here with learning curation strategies and then reviewing the APIs.