whyqd: simplicity, transparency, speed¶
What is it?¶
More research, less wrangling
whyqd (/wɪkɪd/) is a curatorial toolkit intended to produce well-structured and predictable data for research analysis.
It provides an intuitive method for creating schema-to-schema crosswalks for restructuring messy data to conform to a standardised metadata schema. It supports rapid and continuous transformation of messy data using a simple series of steps. Once complete, you can import wrangled data into more complex analytical or database systems.
whyqd plays well with your existing Python-based data-analytical tools. It uses Ray and Modin as a drop-in replacement for Pandas to support processing of large datasets, and Pydantic for data models.
Each definition is saved as JSON Schema-compliant file. This permits others to read and scrutinise your approach, validate your methodology, or even use your crosswalks to import and transform data in production.
Once complete, a transform file can be shared, along with your input data, and anyone can import and validate your crosswalk to verify that your output data is the product of these inputs.
Why use it?¶
whyqd allows you to get to work without requiring you to achieve buy-in from anyone or change your existing code.
If you don't want to spend days or weeks slogging through data when all you want to do is test whether your source data are even useful. If you already have a workflow and established software which includes Python and pandas, and don't want to change your code every time your source data changes.
If you want to go from a Cthulhu dataset like this:
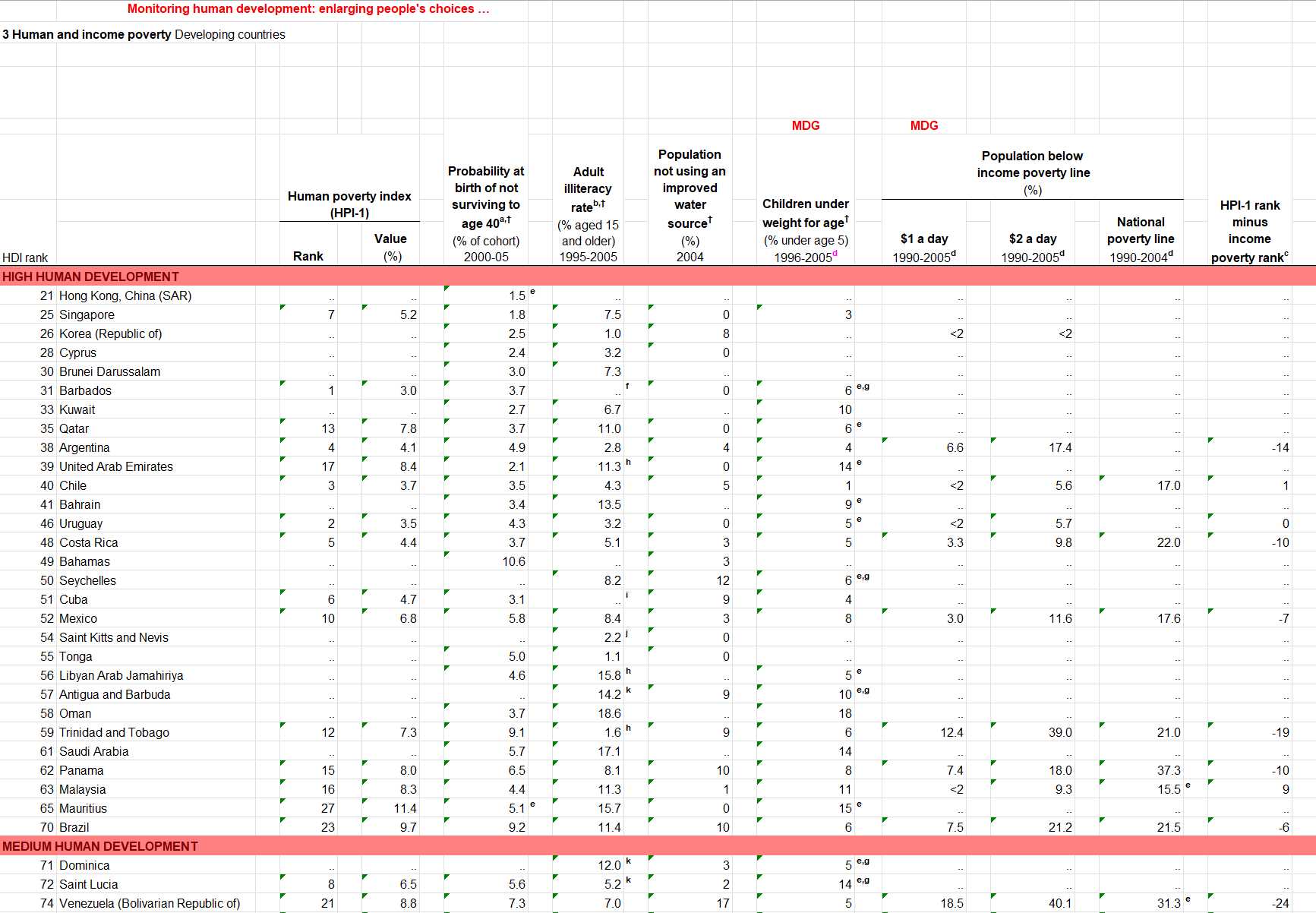 UNDP Human Development Index 2007-2008: a beautiful example of messy data.
UNDP Human Development Index 2007-2008: a beautiful example of messy data.
To this:
| country_name | indicator_name | reference | year | values | |
|---|---|---|---|---|---|
| 0 | Hong Kong, China (SAR) | HDI rank | e | 2008 | 21 |
| 1 | Singapore | HDI rank | nan | 2008 | 25 |
| 2 | Korea (Republic of) | HDI rank | nan | 2008 | 26 |
| 3 | Cyprus | HDI rank | nan | 2008 | 28 |
| 4 | Brunei Darussalam | HDI rank | nan | 2008 | 30 |
| 5 | Barbados | HDI rank | e,g,f | 2008 | 31 |
With a readable set of scripts to ensure that your process can be audited and repeated:
schema_scripts = [
f"UNITE > 'reference' < {REFERENCE_COLUMNS}",
"RENAME > 'country_name' < ['Country']",
"PIVOT_LONGER > ['indicator_name', 'values'] < ['HDI rank', 'HDI Category', 'Human poverty index (HPI-1) - Rank;;2008', 'Human poverty index (HPI-1) - Value (%);;2008', 'Probability at birth of not surviving to age 40 (% of cohort);;2000-05', 'Adult illiteracy rate (% aged 15 and older);;1995-2005', 'Population not using an improved water source (%);;2004', 'Children under weight for age (% under age 5);;1996-2005', 'Population below income poverty line (%) - $1 a day;;1990-2005', 'Population below income poverty line (%) - $2 a day;;1990-2005', 'Population below income poverty line (%) - National poverty line;;1990-2004', 'HPI-1 rank minus income poverty rank;;2008']",
"SEPARATE > ['indicator_name', 'year'] < ';;'::['indicator_name']",
"DEBLANK",
"DEDUPE",
]
Then whyqd may be for you.
How does it work?¶
Definition
Crosswalks are mappings of the relationships between fields defined in different metadata schemas. Ideally, these are one-to-one, where a field in one has an exact match in the other. In practice, it's more complicated than that.
Your workflow is:
- Define a single destination schema,
- Derive a source schema from a data source,
- Review your source data structure,
- Develop a crosswalk to define the relationship between source and destination,
- Transform and validate your outputs,
- Share your output data, transform definitions, and a citation.
It starts like this:
import whyqd as qd
Install and then read the quickstart.
Tutorials
There are three worked tutorials to guide you through three typical scenarios:
Licence¶
The whyqd Python distribution is licensed under the terms of the BSD 3-Clause license. All documentation is released under Attribution 4.0 International (CC BY 4.0). whyqd tradenames and marks are copyright Whythawk.