Derive data & schema models from source data¶
whyqd (/wɪkɪd/) recognises that the world data scientists operate in is far messier than your educators may have led you to believe.
In most cases, standardised schemas are developed post-hoc, after data have been in use for some time. This is simply practical reality. It is often impossible to know what data you need to answer a research question until after you've started trying to answer it.
The majority of tabular data are stored in spreadsheets on people's desktop computers. For most people, Excel is both database and dashboard visualisation software. That also means that source data are designed, foremost, for presentation.
Such data can have any of:
- Merged headers spanning multiple columns and rows
- Random empty rows and columns
- Categorical terms defined as spacers inside data rows instead of as fields
- Joined values containing both quantitative and qualitative data (such as a term and a date)
- Non-numeric data in numeric fields (such as the multiple ways of showing "missing" values)
Instead of fighting to get people, who have other concerns and responsibilities, to adopt some ideal schema, you'll need to study your source and try and identify all the challenges in your way.
You need to derive a schema from data, and then write a crosswalk to get to your archival destination schema standard.
API
Review the class API definitions: DataSourceDefinition.
Derive a data model from source data¶
Assume you have source data defined as follows:
DATASOURCE_PATHis the complete path, or URL to a source data file,MIMETYPEis the source file type, whetherCSV,XLS,XLSX,PARQUETorFEATHER,DIRECTORYand the directory where you want to store your saved output.
Info
whyqd supports any of the following file mime types:
CSV: "text/csv"XLS: "application/vnd.ms-excel"XLSX: "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"PARQUET(orPRQ): "application/vnd.apache.parquet"FEATHER(orFTR): "application/vnd.apache.feather"
Declare it like so:
MIMETYPE = "xlsx" # upper- or lower-case is fine
Specify the mime type as a text string, uppper- or lower-case. Neither of Parquet or Feather yet have official mimetypes, so this is what we're using for now.
Deriving a data model is as simple as:
import whyqd as qd
datasource = qd.DataSourceDefinition()
datasource.derive_model(source=DATASOURCE_PATH, mimetype=MIMETYPE)
datasource.save(directory=DIRECTORY)
datasource.validate()
.save will export a JSON-Schema compliant text file with .data as its filetype. This captures everything about your
source data, including a citation. If your data are accessable via a persistent url, then distributing
this file ensures that all metadata definitions associated with your source data are maintained.
.validate will repeat the derivation and test that the checksum derived for the
model is repeatable.
whyqd can import this file and produce schemas, crosswalks and data transformations.
Warning
If your source data are Excel, and that spreadsheet consists of multiple sheets, then whyqd will produce
multiple data models which will be returned as a list. Each model will reflect the metadata for each sheet.
As always look at your data and test before implementing in code. You should see an additional sheet_name field.
You can read it:
datasource.get.dict(by_alias=True, exclude_defaults=True, exclude_none=True)
{'uuid': UUID('827941cb-fc89-4849-beea-5779fefb9f87'),
'path': DATASOURCE_PATH,
'mime': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',
'columns': [{'uuid': UUID('7809a86c-c888-4f68-8eb2-a53a3e90c569'),
'name': 'Property Reference Number'},
{'uuid': UUID('c4296371-4808-4e28-a04b-680c3ed0cd75'),
'name': 'Primary Liable party name'},
{'uuid': UUID('21688dd3-4b17-4420-8712-d40a85ea13f3'),
'name': 'Full Property Address'},
{'uuid': UUID('4a5ba635-6cdf-49d6-9347-8975cffbab61'),
'name': 'Current Relief Type'},
{'uuid': UUID('c4196d43-8c68-495b-bd1f-0e482485f5a2'),
'name': 'Account Start date'},
{'uuid': UUID('e5ac6524-77c4-4144-878d-5aea44c3ff22'),
'name': 'Current Relief Award Start Date'},
{'uuid': UUID('916b9f15-7638-41e4-96e6-7c1b88ea257e'),
'name': 'Current Rateable Value'}],
'preserve': ['Property Reference Number',
'Primary Liable party name',
'Full Property Address',
'Current Relief Type',
'Account Start date',
'Current Relief Award Start Date',
'Current Rateable Value'],
'attributes': {},
'checksum': 'c1a67eba4344aea0264a2375145ed0991ee7ec29574d04cdeba86e651dede21aa04a00547d121c57c16005c6bfa760b959f9cae116bcaf83dc36fcb1fddb01a4',
'index': 3421}
Strategy
You can edit this data model, changing everything from the default generated name, to the types allocated to each
field. You should definitely update description and give greater depth.
datasource.get.description = "Portsmouth ratepayer data in multiple sheets. Demonstrating create method, add date, actions and perform a merge, plus filter the final result."
But, as far as the data types for each of the columns, I'm going to suggest that you leave this to your schema
definition.
Machine-readability come in a variety of forms. As long as your source data meet the primary requirements of curation, you will be able to perform analysis or transformations. As for coercing your data types? Well, your schema will do that for you.
This derivation assumed a clear header row indexed at 0. Unfortunately, not all source data are so easy.
Derive a minimum transformable schema from ugly data¶
Sometimes your source data are wild.
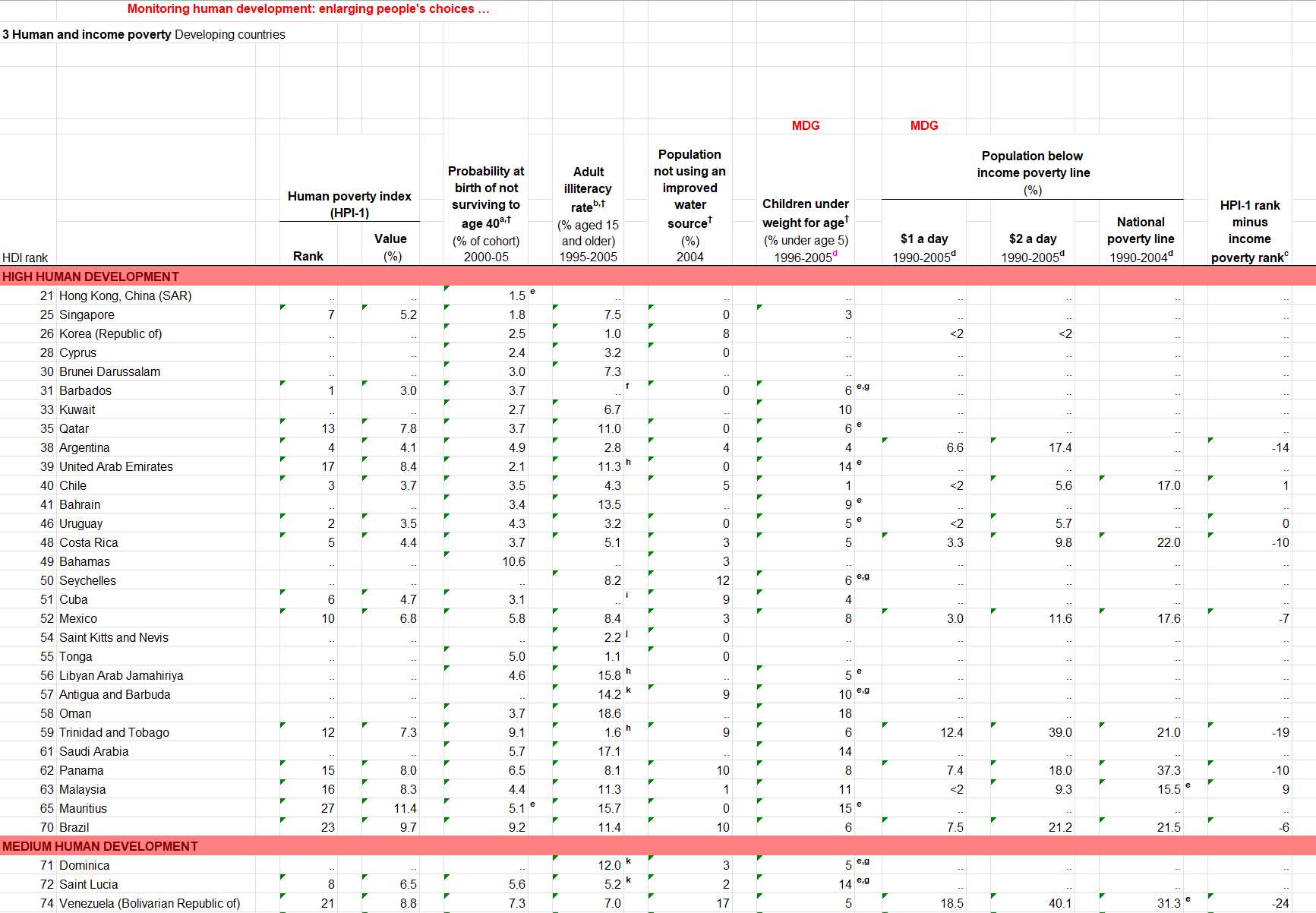
UNDP Human Development Index 2007-2008: a beautiful example of messy data.
The 2007-8 HDI report was listed as a series of about 50 spreadsheets, each dataset aligned with the objectives of the Millennium Development Goals. These supporting information were used to track countries meeting the MDG targets. Analysis required rebuilding these spreadsheets into a single database aligned to a common schema.
The temptation is to dive straight in and start physically restructuring this until you have something that meets the minimum criteria for machine readability. That is unnecessary, and commits the cardinal sin of data curation.
Ethics
Never perform destructive changes to source data.
A destructive change is one which is undocumented, and - therefore - unreproducible by others.
Instead derive a minimum transformable schema as follows:
import whyqd as qd
datasource = qd.DataSourceDefinition()
datasource.derive_model(source=SOURCE_DATA, mimetype=MIMETYPE, header=None)
Row (0-indexed) to use for the column labels of the parsed DataFrame. If there are multiple sheets, then a list of
integers should be provided. If header is None, row 0 will be treated as values and a set of field names will be
generated indexed to the number of data columns.
datasource.data.columns
Index(['column_0', 'column_1', 'column_2', 'column_3', 'column_4', 'column_5',
'column_6', 'column_7', 'column_8', 'column_9', 'column_10',
'column_11', 'column_12', 'column_13', 'column_14', 'column_15',
'column_16', 'column_17', 'column_18', 'column_19', 'column_20',
'column_21'],
dtype='object')
Strategy
The emphasis is on minimum transformable. Your schema is going to need to validate. string field types will
preserve underlying data where a column contains a mix of types. The process of transformation between schemas
permits you to correct problems and restructure your source data. Transformation gets you to where you need to be to
perform more complex data restructuring and analysis.
Further learning
Learn more about transforming Cthulhu data in the full worked tutorial for this dataset.
Derive schema models from data models¶
A data model is useful for ensuring that source data are preserved, but schemas are better for defining data and ensuring validation and compliance with research objectives.
Getting from a data model to a schema definition is straightforward:
import whyqd as qd
datasource = qd.DataSourceDefinition()
datasource.derive_model(source=DATASOURCE_PATH, mimetype=MIMETYPE)
schema_source = qd.SchemaDefinition()
schema_source.derive_model(data=datasource.get)
If you review the Field operations you'll see you can now access the individual fields and apply constraints and defaults.
Here's how you'd derive categorical terms from a data model column:
schema_source.fields.set_categories(name=CATEGORY_FIELD,
terms=datasource.get_data())
Where the CATEGORY_FIELD is a string which identifies which data model column you want to get categorical terms from.
This will identify all the unique terms in that table column and assign them as categorical terms to the field.
You can also specify them as_bool (where terms are [True, False]), or you can treat terms as_array, where a row
may be assigned a list of categorical terms.
An example of both of these types of categorical terms is explained in one of the worked tutorials.
| la_code | ba_ref | occupant_name | postcode | occupation_state | occupation_state_date | prop_ba_rates | occupation_state_reliefs |
|---|---|---|---|---|---|---|---|
| E06000044 | 177500080710 | A company | PO5 2SE | True | 2019-04-01 | 98530 | [small_business, retail] |
Categorical terms are not validated on assignment, so if you choose to set arbitrary terms, that'll happen:
name = "column_1"
st.set_field_categories(name=name, terms=["fish", "frog", "fennel"])
st.schema.fields.get(name=name).dict(by_alias=True, exclude_defaults=True, exclude_none=True)
{'uuid': UUID('a43b7a94-ca6f-438d-83b9-4c84d9d7a0b7'),
'name': 'column_1',
'title': 'column_1',
'type': 'string',
'constraints': {'enum': [{'uuid': UUID('f9032145-6fb9-4873-b314-1a094b79f432'),
'name': 'fish'},
{'uuid': UUID('f88c29f4-809c-4aef-b885-a8e372cba48f'), 'name': 'frog'},
{'uuid': UUID('ab1f0dff-c716-43df-9b00-179f211c7b04'), 'name': 'fennel'}]}}
Strategy
The objective of specifying categorical terms is to support transformation, and associating categorical terms in a source schema with those in a destination schema. You don't need to use all of them, but all terms in a source data column must be listed in the source schema field.
Pandas attributes are available¶
whyqd is NOT an analytical tool. It supports data curation, and so the default behaviours are to preserve source data and do as little as possible during transformation. That said, some source data - especially CSV files - are difficult to read and won't open at all without some help.
As one example, CSV errors in opening a source file can be fixed by referencing quotation and end-of-line errors using
quoting=csv.QUOTE_NONE. "CSV" is often a misnomer. Anything can be a separator, sep='*'.
Arbitrary additional attributes used by Pandas for reading CSVs, Excel and other mime types supported by whyqd can be included without limit:
import whyqd as qd
datasource = qd.DataSourceDefinition()
datasource.derive_model(source=DATA, mimetype=CSVTYPE, quoting=csv.QUOTE_NONE, sep="*")
datasource.validate()
Use this sparingly. Exceptions raised as a result of any additional attributes will be Pandas exceptions.
Schema coersion to source data¶
Your source schema may not correspond to your input data structure immediately, and may need to be coerced. Categorical data may need to be validated, date formats recognised, or integers converted to floats.
whyqd will do this automatically during transformation and your output data will be coerced to their schema-defined types and constraints.
If any data fields do not match, or require coercion to match, then you will receive a warning:
UserWarning: 1 columns in Data were coerced to appropriate dtypes in Schema. ['occupation_state_date']
UserWarning: 2 columns in Data were coerced to appropriate dtypes in Schema. ['occupation_state', 'occupation_state_reliefs']
Hashing for data probity¶
Those of you familiar with Dataverse's universal numerical fingerprint may be wondering where it is? whyqd, similarly, produces a unique hash for each datasource. Ours is based on BLAKE2b and is included in the data source model.
datasource.get.checksum
'a8d03afd7d5b93163dac56ba23a7c75dedf42b8999295e560f3d633d54457e9de3ae95dea8181f238e549a7fba10a36723d2f1b1d94ef3f2273129a58bfc0751'
This is used for validation tests to ensure that source and transformed data both match those originally used and produced as a result of a crosswalk.
Citation¶
whyqd is designed to support a research process and ensure citation of the incredible work done by research-based data scientists.
A citation is a special set of fields, with options for:
- author: The name(s) of the author(s) (in the case of more than one author, separated by
and), - title: The title of the work,
- url: The URL field is used to store the URL of a web page or FTP download. It is a non-standard BibTeX field,
- publisher: The publisher's name,
- institution: The institution that was involved in the publishing, but not necessarily the publisher,
- doi: The doi field is used to store the digital object identifier (DOI) of a journal article, conference paper, book chapter or book. It is a non-standard BibTeX field. It's recommended to simply use the DOI, and not a DOI link,
- month: The month of publication (or, if unpublished, the month of creation). Use three-letter abbreviation,
- year: The year of publication (or, if unpublished, the year of creation),
- licence: The terms under which the associated resource are licenced for reuse,
- note: Miscellaneous extra information.
As an example:
import whyqd as qd
datasource = qd.DataSourceDefinition()
datasource.derive_model(source=SOURCE_DATA, mimetype=MIMETYPE)
citation = {
"author": "Gavin Chait",
"month": "feb",
"year": 2020,
"title": "Portsmouth City Council normalised database of commercial ratepayers",
"url": "https://github.com/whythawk/whyqd/tree/master/tests/data",
"licence": "Attribution 4.0 International (CC BY 4.0)",
}
datasource.set_citation(citation=citation)
You can then get your citation report:
datasource.get_citation()
{'author': 'Gavin Chait',
'title': 'Portsmouth City Council normalised database of commercial ratepayers',
'url': AnyUrl('https://github.com/whythawk/whyqd/tree/master/tests/data', scheme='https', host='github.com', tld='com', host_type='domain', path='/whythawk/whyqd/tree/master/tests/data'),
'month': 'feb',
'year': 2020,
'licence': 'Attribution 4.0 International (CC BY 4.0)'}
This citation support is available in all Definitions, including SchemaDefinition,
CrosswalkDefinition, TransformDefinition, and DataSourceDefinition.